
混合記憶體模塊(Hybrid Memory Cube, HMC)是在一個異構(heterogeneous)的3D封裝中融合最佳的邏輯和DRAM製程技術。此架構的最底層是由邏輯線路所組成,其上則是垂直堆疊的DRAM晶片以穿透矽通孔(through-silicon vias ,TSVs)加以連結,此一優化能量使用效率的DRAM陣列通過內部邏輯層和TSV存取記憶位元-如此構成一個智慧記憶體元件,具有優化的性能和效率。將這些智慧存儲單元放在同一基板上視為一運算單元,每個系統都可以用比過去更有效率的方式執行它們被設計該做的事。具體來說,處理器不再局限於記憶體的通道數量而能夠利用全部的計算能力。 |
|
自計算機時代來臨之後,記憶體技術一直想努力跟上的腳步。在70年代中期的設計和半導體製造技術開始突飛猛進,採用這些尖端技術以增加核心時鐘頻率和電晶體數量。相反的,製造商主要只採用進步的製造技術以迅速且持續地擴大產能。但是隨著越來越多的電晶體被添加到系統之中以提高性能,記憶體產業為了支援這些新架構而在新記憶體系統的設計上卻無法跟上腳步。事實上每向前一個世代,每個核心的記憶體控制器數量就隨之減少,如此一來,記憶體系統的負擔也隨之增加。
為了應付這項挑戰,在2006年美光公司(Micron)在內部組織了數個團隊來檢視不只記憶體性能方面的需求。他們的目的是將整體系統都納入考慮,進而創造出一個平衡的架構以達到更高的系統效能與能力更強的記憶體與I/O系統。混合記憶體模塊(Hybrid Memory Cube, HMC)就是上述努力的成果。它在一個異構(heterogeneous)的3D封裝中融合最佳的邏輯和DRAM製程技術。此架構的最底層是由邏輯線路所組成,其上則是垂直堆疊的DRAM晶片以穿透矽通孔(through-silicon vias ,TSVs)加以連結,如圖1所示。此一優化能量使用效率的DRAM陣列通過內部邏輯層和TSV存取記憶位元-如此構成一個智慧記憶體元件,具有優化的性能和效率。

圖1:HMC具有一小型邏輯層,位於垂直堆疊的DRAM晶片下方,這些晶片是以穿透矽通孔(through-silicon vias ,TSVs)加以連結。
將這些智慧存儲單元放在同一基板上視為一運算單元,每個系統都可以用比過去更有效率的方式執行它們被設計該做的事。具體來說,處理器不再局限於記憶體的通道數量而能夠利用全部的計算能力。以高性能電晶體組成的邏輯晶片是負責DRAM測序(sequencing)、刷新、數據路由、糾錯以及與主體之間的高速互連。HMC的抽離式(abstracted)記憶體架構將記憶體介面與記憶體技術分離,允許不同特性的存儲系統共用使用一個介面。抽離式記憶體設計讓設計者不再需要煩惱記憶體的控制問題,例如糾錯,復原(resiliency)和刷新;反而讓他們更可以善加利用記憶體的特點,例如效能極大化與非揮發特性。由於HMC支持高達160 GB/s持續不變的記憶體頻寬,如此一來該問的問題就成為「你想用多快的速度運行這個界面?」
HMC聯盟
像HMC這樣全新的技術需要一個廣泛的生態系統支持以被主流所採納。針對此一挑戰,美光、三星、Altera、Open-Silicon及Xilinx共同組成HMC聯盟(HMCC),並於2011年10月正式啟動。該聯盟的目標包括匯集眾多的原始設備製造商(OEM)、推動者和工具供應商一起定義出一個可被各界接受的HMC串行介面規範。該聯盟在17個月內完成這項工作,並且在2013年4月推出世界上第一個HMC介面和協議規範。
該規範提供了跨物理層(PHYs)的短距(short-reach, SR)、極短距(very short-reach, VSR)以及超短距(ultra short-reach, USR)的互連能力,適用於需要緊密耦合或近接內存設計的FPGA、ASIC和ASSP應用,例如高性能的網路和計算功能以及測試和測量設備。
聯盟的下一個目標是開發第二套旨在提高數據傳輸速率的協議。在2014年第一季聯盟有望達成協議,此協議預期會讓SR的速度從15 Gb/s提高到28 Gb/s,而VSR/USR的互連速度從10增加至15-28 Gb/s。
架構和性能
HMC與傳統記憶體模組相比還有其他的不同之處,包括原始性能、簡化的電路板佈線以及無與倫比的RAS特性。HMC裝置內獨特的DRAM設計可支持16個獨立且能自行調控的儲存庫(self-supporting vault)。每個儲存庫可持續提供10 GB/s的內存頻寬,因此總和頻寬達160 GB/s。每個DRAM層的每個儲存庫內有兩個內存銀行,一個2GB的元件之內有128個內存銀行,256個內存銀行就構成一個4GB的元件。與傳統以鎖步(lock-step)方式運行的記憶模組相比,由於此新架構具有較低的隊列延遲(queue delay)和更高的數據響應可用性,系統的整體性能顯著提升。不僅可以進行大規模的平行處理,同時HMC支援原子操作(atomics),減少與處理器之間的數據傳輸和無載修復(offload remedial)工作。
正如之前所提到的,抽離式介面與內存無關(memory-agnostic),並採用基於HMCC協議的高速序列匯流排。在此簡單的協議標準中,諸如寫入128位元(WR128)、讀取64位元(RD64)或兩個8位元立即相加的命令(2ADD8)都可隨機混合。該介面可適當地縮放頻寬和功率以適用於任何設計-從所謂「近接存儲器」(即置於緊鄰CPU位置),「遠接存儲器」(即HMC元件可能在遠端以網格網路的形式鏈接在一起)。近接存儲器的配置如圖2所示,遠接存儲器則如圖3所示。此協議同時也支持JTAG和I2C邊帶(sideband)通道功能以優化元件的配置、測試和即時監測。

圖2:HMC與CPU之間的訊號傳輸採用HMC聯盟的協議標準。此處顯示一近接存儲器之配置。
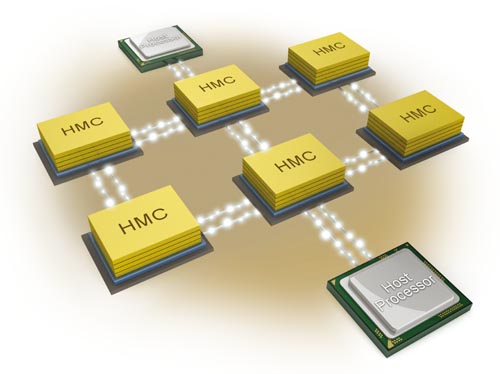
圖3:遠接存儲器之通訊架構。
HMC電路板佈線使用價格低廉並且是標準的高容量互連技術。佈線無需考慮與其他信號間的複雜時序關係,並且顯著減少信號的數量。事實上只要使用262的信號就能夠達到160 GB/s的持續內存頻寬(單鏈路的信號數量為66個,內存頻寬可達60 GB/s)。
一個單一且強大的HMC模組包括記憶體、記憶體控制器以及抽離式介面。如此架構可達到存儲控制器平衡、ECC校正與使用者看不到的數據清理(data scrubbing);另外也達到可自我修正的終身記憶體維護能力;還有監測元件操作的能力以及即時狀態報告。HMC還具有一個十分可靠的外部串行器/解串器(serializer/deserializer, SERDES)介面,具有出色的低誤碼率(bit error rate, BER)也支持循環冗餘校驗(cyclic redundancy check, CRC)和數據封包重試功能。
與一個運行在10.66 GB/s的DDR3-1333模塊相比,HMC可提供160 GB/s的頻寬或者說是15X的效能增強。隨著能源效率是以每位元微微焦耳等級來計算的時候,HMC的工作範圍鎖定在20 pJ/b附近。而DDR3-1333模塊的工作範圍則約60 pJ/b,兩者之間有70%的效率差別。HMC的另一項特徵是針數減少將近90%-HMC的引腳為66個,而一個4通道的DDR3則有約600支引腳。從這些比較中很容易可以看出HMC在性能上的顯著提升同時節省大量的引腳數量和能量耗損。
全文請參閱《半導體科技雜誌 SST-AP Taiwan》
多歷期精采文章,請參閱智權報總覽 >>
|







