人工智慧時代下機器學習(machine learning)的相關發明與傳統電腦程式發明有顯著不同,究竟專利申請人在撰寫該類別的專利請求項與說明書時,要如何呈現才能符合專利充分揭露要件? 本文依序從(1)該人工智慧或機器學習的發明應用於或解決何種問題、(2)該發明使用何種模式結構(model structure)、(3)該模式結構使用何種演算法(algorithm)施以訓練、(4)該用於施以訓練(training,或稱測試)的演算法被給予何種資料數據(data)、(5)該資料數據受何種超參數(hyperparameters)規制、 (6)綜合以上軟體階層如何與硬體結合等概念問題解構並說明之。
圖片來源:CanStockPhoto.
美國法院將專利法第112條第(a)項的充分揭露要件區隔為「可據以實現」和「書面說明」兩個獨立要件,要求專利申請人於說明書應詳實揭露發明內容,使所屬技術領域具有通常知識者(PHOSITA)得製造及使用該發明技術,各請求項也必須為說明書所支持,所請範圍不得超出說明書揭露的內容[1] 。針對軟體設計領域具體來看,充分揭露要件對軟體發明的要求可著重於(1)檢視該發明請求項是否敘述所請軟體發明具備的功能,(2)說明書是否闡明如何達到前述請求項對該軟體發明具備的功能劃出的權利範圍。
機器學習不同於傳統電腦程式發明
未如傳統電腦程式發明的運算機制通常可被預測和清楚描繪,機器學習會基於應用基礎不同,改變運算過程中的解決方案(solution),故運算過程具不確定性。具體而言,機器學習在運算過程中並非單純重複地處理資料庫問題,其可從接受的資料或經驗選取出部份予以最佳化,故設計者得塑造一具有演算法執行的模式(model),並以不同的參數(parameters)給予獨立定義;是以,所稱「學習」,就是讓該模式以設定的演算法予以執行。通常設計者會利用「訓練用數據資料」(training data)最佳化參數,等到訓練用數據資料累積一定程度後,參數價值也因最佳化結果逐漸提高。換句話說,機器學習的模式是由參數所定義,參數的價值來自訓練用數據資料的持續餵養(feed)、將之最佳化的結果。因此,不同的訓練用的數據資料或不同的模式設計都將造成機器學習在執行演算後不同的最終結果。
從專利授予的角度言之,機器學習系統的開放性和其缺乏經演繹而不可預測的本質,相較於傳統僵化的程式運算對適應新情境或新識別方案時執行效率都較為良好,而這些本質就直接關乎於專利充分揭露要件對請求項和說明書撰寫上的要求與檢核。
由於一新發明得同時符合不同機器學習的模式結構或訓練用演算法,故建議該發明可以該模式或演算法的「功能特性」請求專利,因此在撰寫專利申請時,該專利說明書需完整闡述如何達到該些「功能」或「結果」;更有甚者,由於該些參數價值來自於反覆實驗性操作而得以最佳化,因此說明書必須提供足夠的解釋或範例指引,以證明上述這些操作不需過度實驗(undue experimentation)即可達成。
從經典判決先例出發:解決何種問題、模式結構與演算法的揭露
聯邦巡迴上訴法院(CAFC)在1997年Genentech, Inc. v. Novo Nordisk A/S案指出,說明書應揭露包含「特定起始材料(starting material)」和「執行過程的狀態或條件」[2] 。此對機器學習發明來說,就是指「要被解決的問題或被使用的模式結構」和「用於最佳化參數的訓練過程和方法」,故說明書應至少揭露適用模式的特性(characteristics)和用於訓練該模式的演算法,甚且若是超過一種模式或多種演算法可以適用該發明,則該些備選模式或演算法都應予揭露;另由於「要被解決的問題」可能限制模式或演算法的設計,因此該欲解決的目標應也需要明確的指明。
在1988年In Re Wands此經典案例中,CAFC提出評估系爭專利請求項是否需過度實驗方能據以實現的八項因子,為避免說明書對機器學習的敘述過於抽象,其中四項因子對判定人工智慧或機器學習發明的專利是否得據以實現相當關鍵。除發明本質(the nature of the invention)外,包含有無操作實施例(working examples)、實驗所耗費的時間和金錢(the quantity of experimentation necessary)和專利申請所呈現指示或指導的數量(the amount of direction provided by the inventor)[3] ,在撰寫說明書時都應該留意之。
施以何種訓練用資料數據和超參數的揭露
一旦識別出機器學習的發明所採行的模式態樣和訓練用之演算法,發明人通常下一步考慮的就是應使用何種類型的「訓練用資料數據」。以專利說明書轉寫角度觀之,包含數據量的大小、來源和可否接受多來源的原始數據(raw data)等因素應為適當揭露。
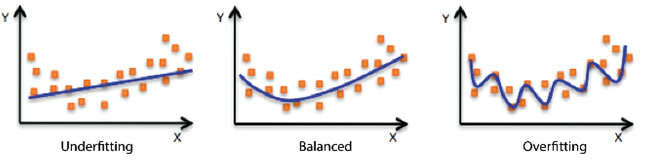
首先,申請人應注意的就是數據量的「大小」。數據量太少會造成訓練資料和評估值間的預測誤差,例如模式產生「低度擬合」(underfitting),此時由於模式無法擷取輸入範例(通常稱為 X)和目標值(通常稱為 Y)之間關係模式,執行效能不佳;或產生「過度擬合」(overfitting),此時雖有良好執行效果,但模式僅能讀取資料,無法一般化未知的範例[4] 。數據量太多或許只需在適當時間點停止施以資料數據,但過程中無法獲知系統記憶體和運算資源是否足以支撐而產生誤差。
此外,申請人應考量資料數據的「來源」,從公共領域直接蒐集的數據資料並未被良好處理或標示,因此,若機器學習的發明人有特定資料數據的來源應予以揭露,若無指定來源,在撰寫說明書時應著墨所請發明應用的資料數據來源或可被接受的數據特性,以利審查官或PHOSITA在閱讀該專利時得以識別該來源。最後,由於特定演算法僅能運行單一或處理過後的資料數據,若數據來自多個不同來源,則該些蒐集來的資料須要先經過規範化(canonicalized),因此,所請發明可否接受多來源的原始數據也受 PHOSITA 注目,故應完整揭露於專利說明書 。
超參數則用於規制機器學習模式對訓練用資料數據的反應。換句話說,超參數描述機器學習模式的樣貌且不會被演算法執行時所影響,例如超參數控制著在類神經網絡(neural network)的層數(layers)和節點(nodes)中資料數據的交會,因此超參數如何被設定和設定方法應該在專利說明書中揭露,甚至提出實施例。
機器學習下的軟硬體結合 在軟體領域的發明專利重視軟硬體間的互動關係(interrelationship),
小結
本文循序漸進將人工智慧時代下機器學習予以解構,並指出在撰寫專利說明書時應注重之處,以避免未適當揭露而使所申請之發明無法據以實現或說明書未充分支持請求項範圍,而導致專利申請在審查時被核駁或在執行權利時因未滿足充分揭露要件而被舉發無效。
台灣法則依專利法第26條第2項後段:「其得包括一項以上之請求項,各請求項應以明確、簡潔之方式記載,且必須為說明書所支持。」,稱之「支持要件」。參見「發明專利實體審查基準」,經濟部智慧財產局,2013 年版,第二篇第一章第2.3.4 節,第2-1-31 頁。
Genentech, Inc. v. Novo Nordisk A/S, 108 F.3d 1361 (Fed.Cir.1997) (“the specification should disclose specific starting material and the conditions under which a process can be carried out.”)
其他四個因子分別為既有的技術水準、該領域中相關之技術、該技術是否具有預期性、申請專利的範圍。In Re Wands, 858 F.2d 731, 737 (Fed. Cir. 1988).
模式擬合:低度擬合與過度擬合模型擬合,Amazon Machine Learning開發人員指南,Amazon Web Services, Inc.,https://docs.aws.amazon.com/zh_tw/machine-learning/latest/dg/model-fit-underfitting-vs-overfitting.html (最後瀏覽日期:2019年4月20日)
【本文僅反映專家作者意見,不代表本報立場。】
作者: 李秉燊
現任: 美國杜克大學法學院訪問學者
學歷: 國立交通大學科技法律研究所博士生
專業資格: 107年度中華民國專利師考試及格
Facebook 在北美智權報粉絲團上追踪我們
Please enable JavaScript to view the comments.